IEDGE – Herramientas de Data Mining
Para decidir cuál es la técnica más adecuada para resolver una determinada situación, es necesario distinguir el tipo de información que se desea extraer de los datos. Según su nivel de abstracción y el conocimiento contenido en los datos, puede clasificarse en distintas categorías:
- Conocimiento evidente: Información fácilmente recuperable con una simple consulta (query). Ejemplo: ¿Cuáles fueron las ventas del mes 1?
- Conocimiento multidimensional: Consiste en considerar los datos con una cierta estructura, permitiendo diferentes niveles de detalle. Este tipo de información es la que analizan las herramientas OLAP. Ejemplo: Partiendo de la información anterior de ventas del mes 1, consultar sólo las ventas del producto X en la provincia Y.
- Conocimiento oculto: Información evidente, desconocida a priori y potencialmente útil que puede recuperarse mediante técnicas de minería de datos. Esta información es de gran valor porque abre una nueva visión del problema. Ejemplo: ¿Cuál es el perfil de los clientes del producto X?
Las herramientas de modelización pueden dividirse en dos grupos: basadas en la teoría estadística y aplicadas en base a datos (técnicas de inteligencia artificial).
1. Herramientas de modelización teórica
- Técnicas de correlación de datos: Es una medida de relación entre dos variables. La correlación puede ser positiva o negativa. Una correlación positiva indica que un nivel alto de una variable se acompañará por un valor también alto de la variable correlacionada. Una correlación negativa indica que un nivel alto de una variable se acompañará por un valor bajo de la variable en correlación. Una aplicación de esta técnica es el análisis de los productos que se compran juntos en el carro de la compra.
- Regresión lineal: La regresión lineal es un método que traza una línea recta a partir de los datos, minimizando la suma de las distancias de los puntos a la propia recta. Si la pendiente de la línea es positiva (hacia arriba), significa que una variable independiente, como por ejemplo el tamaño de la fuerza de ventas, tiene un efecto positivo en una variable dependiente, como puede ser los ingresos. Si la pendiente es negativa (hacia abajo) hay un efecto negativo. La inclinación de la recta será mayor cuanto mayor sea la influencia de la variable independiente sobre la dependiente.
- Métodos de predicción: Consiste en tomar datos históricos de una variable determinada, por ejemplo las ventas, y proyectar dicha variable en el futuro. Hay numerosos métodos de predicción, que incluyen técnicas de regresión de series temporales y redes neuronales. Muchas de esas técnicas pueden recoger tanto tendencias lineales a largo plazo, como fluctuaciones cíclicas a corto plazo.
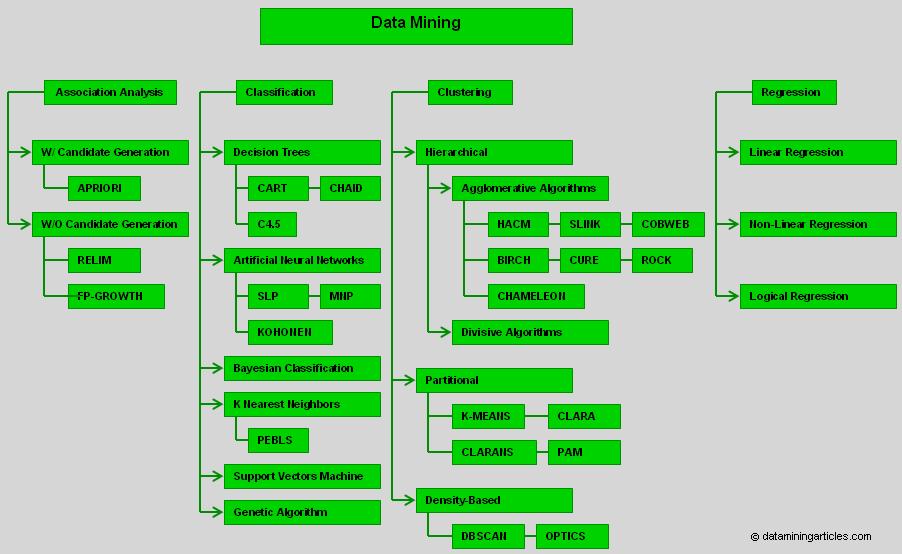
2. Herramientas de modelización basadas en los datos
- Análisis cluster: Es una técnica de reducción de datos que agrupa elementos basados en características similares. Los elementos de cada conglomerado son lo más parecidos posible entre sí, y lo más diferenciados posible respecto a los elementos de los otros conglomerados. Esta técnica es muy útil para encontrar segmentos de clientes basándonos en características demográficas, financieras, etc.
- Árboles de decisión: Los árboles de decisión agrupan los datos en conjuntos, cuyas reglas tienen un efecto distinto en una variable objetivo. Por ejemplo, podemos buscar las características de una persona que respondería con mayor probabilidad a una acción de marketing directo, maximizando la efectividad de nuestras campañas. Estas características podrían ser trasladadas a un conjunto de reglas. Se trata pues de identificar los segmentos de clientes que, basándose en campañas previas, es más probable que respondan a una promoción similar. Esto se realiza buscando las combinaciones de variables que mejor distingan a aquellos clientes que respondieron a la promoción anterior de aquellos que no lo hicieron.
- Redes neuronales: Son modelos de datos que simulan la estructura del cerebro humano. Las redes neuronales aprenden a partir de un conjunto de entradas, y ajustan los parámetros del modelo según esta nueva información para hallar patrones en los datos.
- Las redes neuronales son no lineales por construcción, pero no requieren una especificación explícita de una forma funcional (tal como cuadrática o cúbica) como sucede en la regresión no lineal. La ventaja es que no se necesita tener en mente un modelo concreto al ejecutar el análisis. Además, la red neuronal puede encontrar efectos colaterales inesperados, que han de ser especificados explícitamente para tenerlos en cuenta en la regresión.
- La desventaja reside en la complejidad para interpretar el modelo resultante, como consecuencia de los sucesivos y complicados cálculos. Por este motivo, son útiles para predecir un objetivo variable cuando los datos son altamente no lineales e interrelacionados, pero no son adecuadas cuando sea preciso explicar las relaciones entre datos.
- Es una herramienta adecuada para la predicción, modelos de respuesta, análisis de riesgo y asignación de crédito.
- Inducción de reglas: Es una de las formas más comunes de descubrimiento de conocimiento. Es una técnica que sirve para descubrir en los datos un conjunto de reglas del tipo “si – entonces” asignando una determinada probabilidad al caso. Es una técnica potente, debido a que busca todos los patrones posibles, probada (los algoritmos a utilizar están disponibles desde hace muchos años), y de fácil comprensión para el usuario. Sin embargo, puede generar un número muy grande de reglas, muchas de las cuales son obvias, otras son irrelevantes y algunas pueden ser incluso contradictorias entre sí. También podrían no cubrir todas las situaciones posibles.
- Modelos de asociación: Son modelos que examinan en qué medida los valores de un campo dependen de, o se predicen por, valores de otro campo. Estos modelos descubren reglas acerca de artículos que aparecen juntos en transacciones de compra. Son muy apropiados para analizar la cesta de la compra. Se utilizan sobre todo en estudios de empresas de distribución, para analizar patrones de compra y decidir la ubicación de los productos en el establecimiento.
¡Quedo a la espera de sus comentarios!
Profesor de Dirección de Marketing
Nota: Para aprender de una forma práctica y rápida como poner en marcha, desarrollar y controlar planes de marketing directo totalmente eficaces, les invitamos a que consulten la Especialidad Europea en Marketing Relacional.
* Los contenidos publicados en este post son responsabilidad exclusiva del Autor.
¡Pronto grandes sorpresas en Facebook, Twitter y Youtube!: