
[lwptoc depth=»2″]
En el post sobre Estándares para la Gestión de TI describíamos el ciclo de vida de los proyectos tal y como lo describe el PMBOK, es decir, Inicio – Planificación – Ejecución – Cierre. Ya advertíamos en ese post que no se debe confundir este ciclo de vida de los proyectos con las fases o etapas de la ejecución del proyecto como tal.
Ahora, de la mano de la ingeniería de software vamos a dar un repaso al ciclo de vida del desarrollo de software, es decir, al “Marco de referencia que contiene los procesos, las actividades y las tareas involucradas en el desarrollo, la explotación y el mantenimiento de un producto de software, abarcando la vida del sistema desde la definición de los requisitos hasta la finalización de su uso” (definición de la norma ISO 12207-1).
Lo organicemos como lo organicemos, cualquier proceso de desarrollo de software tiene más o menos los siguientes elementos:
La organización de estos elementos definen los diferentes modelos del ciclo de vida del desarrollo de software que se han ido utilizando a través del tiempo en las diferentes organizaciones. Vamos a dar un repaso a algunos de estos modelos.
Aunque parezca increíble, más de un desarrollo se realiza en base a programar y probar, sin una definición clara de los objetivos o un diseño general de las diferentes piezas.
En muy pocas ocasiones da buen resultado y sólo es práctico en el caso de que el usuario y el programador sean la misma persona. En este desarrollo de tipo “personal” se puede encontrar sistemas de macros en Excel, desarrollos de aplicaciones en Access o pequeñas utilidades de productividad personal, pero no es, en general, un modelo aplicable a nivel empresarial.

Ilustración 1: Ciclo de vida primitivo
Este modelo de ciclo de vida en cascada fue creado por W.W. Royce [1970], y ha sufrido innumerables versiones y adaptaciones posteriores. Se caracteriza por estar compuesto por una serie de fases que se ejecutan secuencialmente. Cada fase finaliza con la obtención de productos que son utilizados en la fase siguiente
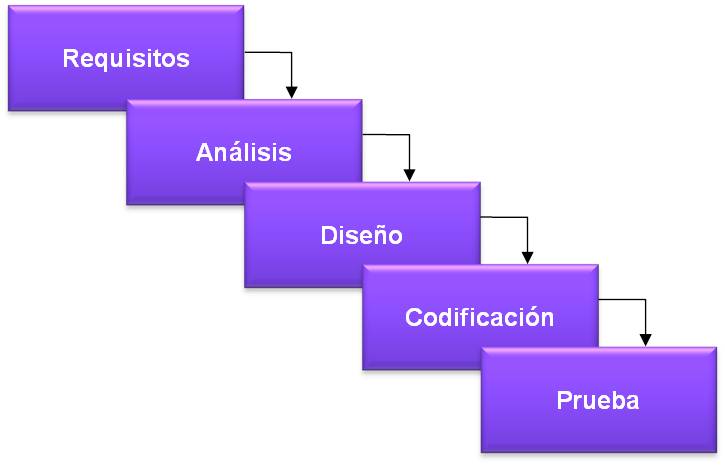
Ilustración 2: Ciclo de vida clásico o en cascada
Este ciclo de vida ha sido especialmente discutido y rechazado por muchas generaciones de programadores, si bien sus principios básicos se recogen en todos los modelos posteriores. Su principal pega es la dificultad de realizar “correcciones hacia arriba”, hacia las etapas anteriores del proceso, es decir, si en el diseño se detecta un error o conflicto en el análisis, es muy complicado volver atrás, ya que esa fase se ha dado por concluida y por lo tanto no se puede reabrir con facilidad.
No debemos rechazar este método sin más, sólo hay que tener en cuenta la posibilidad de poder revisar en fases posteriores el trabajo ya realizado. En desarrollos conocidos y estables es un método utilizado con éxito, sobre todo en grandes sistemas donde prácticamente toda la funcionalidad debe estar disponible desde la primera versión.
En la práctica casi todos los proyectos no cubren todos los requisitos en su primera versión, por lo que una vez realizada una entrega se vuelve a abordar una versión posterior que incluye nuevas funcionalidades. Asumir que esto es así desde un principio es lo que plantea el ciclo de vida iterativo: que una vez realizada la integración o entrega de una versión, se volverá a la fase de análisis para seguir avanzando en el desarrollo.
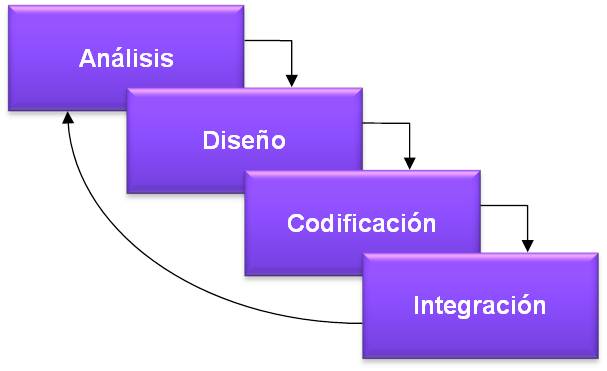
Ilustración 3: Ciclo de vida iterativo
Este tipo de ciclo de vida también tiene sus peligros, ya que puede convertirse en un ciclo sin fin y las entregas terminan quedando sin contenido, ya que prácticamente todo se queda siempre para la versión posterior, por lo que la gestión de las expectativas de los usuarios y clientes puede llegar a ser complicada si no se gestiona por medio de una comunicación y planificación clara. Con la adecuada comunicación y gestión de expectativas es un modelo muy útil para ir avanzando en la construcción de sistemas complejos de forma paulatina.
En el próximo post les hablaré de la evolución de los ciclos de vida de desarrollo de software: Ciclo de vida en espiral y sus variantes RAD y RUP
¡Quedo a la espera de sus comentarios!
Profesor de Dirección de Sistemas y Tecnologías de la Información

Además, hemos abierto el plazo de solicitud de BECAS -100% en los siguientes programas para profesionales: Máster en Marketing Digital, en el Máster en Growth Hacking & Marketing Automation, en el Máster en Digital Analytics & Big Data, en el Máster en eCommerce y en el Máster en Google Marketing Platform.
Cada año formamos a miles de alumnos en estas áreas de conocimiento. ¡Mejora en tu carrera profesional y solicita tu plaza!. Plazas limitadas por edición e IEDGE Business School se reserva el derecho de admisión.

Como continuación del post ¿Qué es un sistema de información?, me gustaría avanzar añadiendo que un sistema de información típico se apoya en tres Componentes de la tecnología: el hardware, constituido por todos aquellos elementos que pueden “tocarse” físicamente; el software (los programas), y las tecnologías de redes, necesarias para conectar diferentes máquinas.
[lwptoc]
Existen diferentes categorías de hardware que resumimos a continuación:
Mostramos a continuación ejemplos de cada categoría:
El software o programas con el conjunto de instrucciones que ejecutadas por los ordenadores, definen nuestra experiencia de uso. Debemos distinguir entre software de sistemas y software de aplicación.
El tercer elemento necesario para cualquier Sistema de Información son las redes de comunicación que hacen posible el intercambio de datos entre diferentes ordenadores. Las redes pueden clasificarse en dos grandes grupos:
Las redes LAN suelen contar con una pieza de hardware fundamental para aumentar el uso eficiente de una red: el intercambiador (switch) que se encarga de poner orden entre los miles o millones de mensajes que se envían a través de la red, cribándolos y dirigiéndolos a segmentos concretos de la red local. Una LAN se puede conectar con otras redes públicas mediante otra pieza de hardware: el encaminador (router), un ordenador especializado en gestionar el intercambio de datos entre redes.
Al hablar de redes, no podemos ignorar la red más grande del mundo: Internet. Internet es una red de redes interconectadas para formar una sola entidad. Ello es posible gracias a la existencia de una serie de políticas y protocolos que definen como usamos e interactuamos con Internet. En el próximo post trataré explicar su funcionamiento básico.
¡Quedo a la espera de sus comentarios!
Profesor de Dirección de Sistemas y Tecnologías de la Información
¡Puedes seguirnos en Linkedin, Facebook, Twitter, Instagram y Youtube!
Puedes asistir a nuestras clases en directo relacionadas con Marketing Digital y Comercio electrónico que organiza IEDGE Business School. Haz clic aquí para ver las próximas masterclass online.

Además, hemos abierto el plazo de solicitud de BECAS -100% en los siguientes programas para profesionales: Máster en Marketing Digital, en el Máster en Growth Hacking & Marketing Automation, en el Máster en Digital Analytics & Big Data, en el Máster en eCommerce y en el Máster en Google Marketing Platform.

Cada año formamos a miles de alumnos en estas áreas de conocimiento. ¡Mejora en tu carrera profesional y solicita tu plaza!. Plazas limitadas por edición e IEDGE Business School se reserva el derecho de admisión.

[lwptoc depth=»2″]
La colección de datos conocida como base de datos es de vital importancia en cualquier empresa. El Sistema Gestor de Bases de Datos (SGBD) permite almacenar y recuperar la información de la base de datos de forma eficiente y práctica. Por debajo de la estructura de la base de datos, se encuentra el modelo de datos, que engloba una colección de herramientas conceptuales para describir los datos, las relaciones, la semántica y las restricciones de inconsistencias. Estas son algunas de las características más eficientes del Modelo entidad-relación:

Una entidad es un ente que se puede distinguir de cualquier objeto. El ejemplo más claro lo define una persona con su DNI, nacido en una localidad determinada en una fecha determinada. Todos estos datos conforman una entidad que identifica únicamente a una persona.
Un conjunto de entidades es un grupo de entidades que comparten las mismas propiedades. Podría ser un ejemplo de conjunto de entidades el alumnado de un colegio.
Cada entidad se compone de atributos. Un atributo es cada una de las propiedades del conjunto de entidades. Siguiendo el ejemplo del alumnado, podríamos hablar de los siguientes atributos: DNI, nombre, dirección y fecha de nacimiento. Cada entidad tiene unos determinados valores para cada uno de los atributos de la tabla. El conjunto de valores permitidos para cada uno de los atributos se conoce con el nombre de dominio o conjunto de valores.
Un atributo en el modelo entidad.relación puede ser de varios tipos:
Una vez definidas las diferentes entidades, podemos realizar asociaciones entre las mismas; lo que se conoce con el nombre de relación. Ej: el alumno 1 asiste a la asignatura 1. La relación puede tener atributos incluidos (por ejemplo nota que sería la calificación del alumno para esa asignatura).
Un conjunto de relaciones es un grupo de relaciones del mismo tipo. Si definimos la entidad matrícula, podríamos representar la asociación entre los alumnos y todas aquellas asignaturas en las que se encuentra matriculados.
A continuación definimos clave como el conjunto de uno o más atributos que permiten identificar de forma única a una entidad del conjunto de entidades. Es importante que el ningún subconjunto de atributos puede ser a su vez clave. Ej: el DNI. La clave principal identifica la entidad del conjunto de entidades y clave externa, es el conjunto de atributos de una entidad que son clave primaria en otra entidad.
El diagrama de entidad-relación representa el modelo gráficamente, mediante el uso de rectángulos, elipses, rombos, líneas,…. Ejemplo:
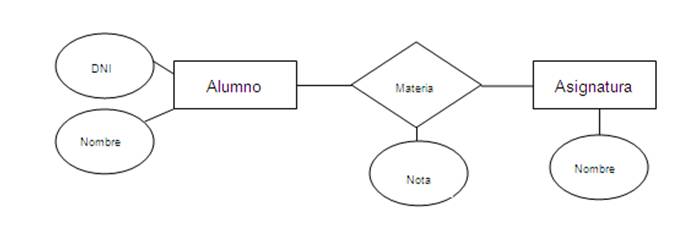
Las entidades al relacionarse con otras entidades pueden tener restricciones. La cardinalidad expresa el número de entidades a las que otra entidad puede estar asociada. Puede ser de 3 tipos:
– Relación uno a uno

– Relación uno a muchos

– Relación muchos a muchos
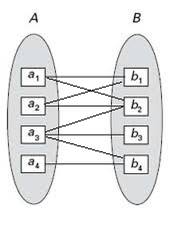
Cualquier modelo entidad-relación, se puede representar por tablas relacionales, teniendo en cuenta:
Los conjuntos de entidades y relaciones pueden definirse de varias formas, por lo que es necesario examinar las siguientes cuestiones a la hora de diseñar un esquema de base de datos:
Existen unas características extendidas del modelo entidad-relación para poder reflejar las características de las bases de datos, y son:
Muchas gracias y esperamos sus comentarios!
Profesor de Dirección en Tecnología y Sistemas de Información
¡Puedes seguirnos en Linkedin, Facebook, Twitter, Instagram y Youtube!
Puedes asistir a nuestras clases en directo relacionadas con Marketing Digital y Comercio electrónico que organiza IEDGE Business School. Haz clic aquí para ver las próximas masterclass online.
Además, hemos abierto el plazo de solicitud de BECAS -100% en los siguientes programas para profesionales: Máster en Marketing Digital, en el Máster en Growth Hacking & Marketing Automation, en el Máster en Digital Analytics & Big Data, en el Máster en eCommerce y en el Máster en Google Marketing Platform.
Cada año formamos a miles de alumnos en estas áreas de conocimiento. ¡Mejora en tu carrera profesional y solicita tu plaza!. Plazas limitadas por edición e IEDGE Business School se reserva el derecho de admisión.

[lwptoc]
Cuando miles de empresas y organizaciones en cientos de países se encuentran con los mismos problemas en la gestión de sus los Proyectos Informáticos y en general con la gestión de las Tecnologías de la Información, uno se pregunta si no existirán soluciones ya probada y suficientemente extendida como para que no tengamos que “inventarnos” nosotros una solución desde cero.
La buena noticia es que existen buenas prácticas y estándares para la Gestión de Proyectos, Gestión de los Servicios y en general para la Gestión de los Departamentos de TI. La mala noticia es que no hay un solo estándar, hay prácticamente cientos.
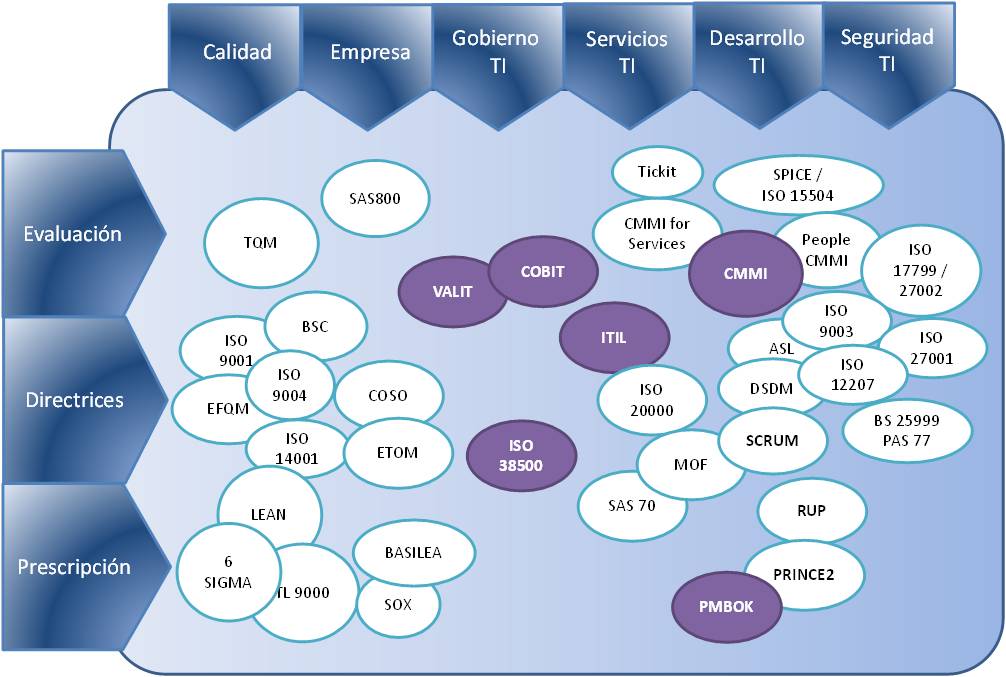
Ilustración 1: Estándares relacionados con la Gestión de las Tecnologías de la Información
En este gráfico se recoge de forma sucinta algunos de los estándares más difundidos que tienen relación con la gestión de TI, desde estándares de calidad como TQM o 6 Sigma que son aplicados en empresas y departamentos de informática como medio de mejora, a sistemas de control empresarial como SOX en Estados Unidos o BASILEA en Europa que van incorporando cada día más controles operativos que afectan a TI; pasando por estándares de gestión o Gobierno de TI como función específica dentro de las empresas como VALIT o ISO38500; siguiendo por estándares de Auditoría Informática como COBIT; guías de Gestión de Servicios de TI como ITIL o de Madurez en el Desarrollo como CMMI; hasta llegar a marcos de referencia para la Gestión de Proyectos (no necesariamente informáticos) como PMBOK o PRINCE2, o metodologías orientadas al Desarrollo de Software como RUP o SCRUM.
Sólo dar un vistazo a este tipo de cuadro produce bastante desconcierto, he incluso un poco de vértigo. Todos desearíamos que fuera más sencillo, que hubiera una norma, una guía o un estándar que todos pudiéramos seguir y de esta forma garantizar el éxito de nuestros proyectos.
La realidad es que no existe una respuesta sencilla y además, hay muchas organizaciones más o menos interesadas en darnos una respuesta. Debemos entender que detrás de todo estándar, guía o norma existen una gran cantidad de certificaciones, cursos y servicios que hacen ganar dinero a bastante gente. Muchas de estas guías, normas y estándares son útiles, pero también esconden ciertos costes que debemos pagar para poder aprovecharlas.
Para complicarlo un poco más, algunos de estos estándares y normativas han producido casos de burocratización excesiva de la gestión, cargando de documentos y controles los procesos, pero sin producir realmente un efecto realmente significativo sobre el éxito de los proyectos.
Vamos a intentar despejar un poco este mare magnum de siglas y veamos algunos de los estándares y normativas más extendidas y más útiles de las que se utilizan en los diferentes niveles de Gestión de los Sistemas y Tecnologías de la Información, desde el Gobierno de TI hasta la Gestión de Proyectos.
El Gobierno de las Tecnologías de la Información o Gobierno de TI es, según el IT Governance Institute (ITGI), es el conjunto de herramientas y métodos “que ayuda a la Alta Gerencia asegurar que la organización obtenga un óptimo valor de sus inversiones de negocio relacionadas a TI, a un costo manejable y bajo un nivel de riesgo aceptable”. Es por lo tanto el gobierno de más alto nivel de la gestión de las tecnologías de la información, aquel que permite alinear los objetivos de negocio y los objetivos de la empresa.
Entre los estándares que han surgido en este nivel de Gobierno de TI podemos destacar VALIT, creado por el ITGI, y que organizar el conjunto total de prácticas de la dirección de TI en tres áreas:
Recientemente se ha publicado un estándar ISO sobre el Gobierno de TI, la ISO/IEC 38500:2008 – IT Governance Standard. Esta norma agrupa una gran cantidad de estándares dispersos y ofrece un marco general de referencia para la dirección de los Sistemas de Información y la Tecnologías de la Información en las empresas y organizaciones, que está teniendo una gran acogida en el mercado.

Ilustración 2: Esquema de la ISO/IEC 38500:2008 (fuente AENOR)
Para más información sobre VALIT pueden consultar www.itgi.org/valit/index.html
Para más información sobre ISO/IEC 38500:2008 pueden consultar http://www.38500.org/ y http://www.iso.org/iso/catalogue_detail?csnumber=51639
El estándar más ampliamente difundido y utilizado para la Auditoría de TI es COBIT, creado por la ISACA. Está guía va mucho más allá de la auditoría, y de hecho es utilizada por muchas organizaciones como una guía de buenas prácticas en la Gestión de los Sistemas y las Tecnologías de la Información.
La guía de COBIT es realmente completa, además de ser muy madura (ya se ha publicado su versión 5). Cubre prácticamente todos los aspectos que se deben tener en cuenta para una correcta gestión de los Sistemas y Tecnologías de la Información en una empresa u organización.

Ilustración 3: El Cubo de COBIT (fuente ISACA)
Para más información sobre COBIT pueden consultar http://www.isaca.org/COBIT
Si vamos “descendiendo” dentro de las actividades de gestión de los departamentos de TI, nos encontramos que prácticamente la totalidad de sus procesos pueden ser descritos como servicios que prestan estos departamentos al conjunto de la empresa. Siguiendo esta orientación a servicios fue creado ITIL (Information Technology and Infraestructure Library) por la Central Computer and Telecommunications Agency (CCTA) del Gobierno Británico.
Este es un estándar ampliamente reconocido para la gestión de los servicios de TI, orientado a conseguir un alto nivel de disponibilidad de dichos servicios y un alto nivel de satisfacción de clientes y usuarios de estos servicios.
Los procesos ITIL están alineados con el estándar de calidad ISO 9000 y se encuentran vinculados con el Modelo de Excelencia de la EFQM (European Foundation for Quality Management), además de haber sido adoptados por el estándar ISO 20000.
Les recomendamos que lean el post “IEDGE – Fundamentos de la Gestión TI” en donde se hace una descripción de ITIL.
Para más información sobre ITIL también pueden consultar http://www.itil-officialsite.com/
En el siguiente post continuaremos esta descripción de los principales estándares para la Gestión de TI, en concreto veremos CMMI como modelo de madurez en el desarrollo de software y PMBOK como guía para la gestión de proyectos.
¡Quedo a la espera de sus comentarios!
Profesor de Dirección de Sistemas y Tecnologías de la Información
¡Puedes seguirnos en Linkedin, Facebook, Twitter, Instagram y Youtube!
Puedes asistir a nuestras clases en directo relacionadas con Marketing Digital y Comercio electrónico que organiza IEDGE Business School. Haz clic aquí para ver las próximas masterclass online.
Además, hemos abierto el plazo de solicitud de BECAS -100% en los siguientes programas para profesionales: Máster en Marketing Digital, en el Máster en Growth Hacking & Marketing Automation, en el Máster en Digital Analytics & Big Data, en el Máster en eCommerce y en el Máster en Google Marketing Platform.
Cada año formamos a miles de alumnos en estas áreas de conocimiento. ¡Mejora en tu carrera profesional y solicita tu plaza!. Plazas limitadas por edición e IEDGE Business School se reserva el derecho de admisión.
La arquitectura de un sistema trata de describir, tanto desde un punto de vista físico como lógico, la forma en la que trabajan los diferentes componentes del mismo.
[lwptoc]
Existen diferentes tipos de arquitecturas de sistemas cuya estructura varía en función de las necesidades de las empresas y del momento histórico en el que se introdujeron. Vamos a describir de forma esquemática las visiones lógica y física de las mismas.
Con independencia de la implementación física, se puede realizar una subdivisión lógica de los sistemas de información en tres niveles:
Esta subdivisión es fundamental para entender la evolución de las arquitecturas.
Su implementación física consiste en disponer de un gran ordenador central (mainframe) que sirve a cientos o miles de usuarios conectados al mismo a través de una pantalla “tonta” (dumb terminal) que se utiliza para entrar o actualizar datos y acceder a información en el mainframe. Tanto la interfaz de usuario como las reglas de negocio y los datos residen en la misma máquina. Se produce, en consecuencia, un acoplamiento de niveles.
IBM popularizó en los setenta este tipo de arquitectura para satisfacer las necesidades de procesamiento grandes corporaciones. Sin embargo, en la actualidad muy pocas organizaciones utilizan exclusivamente este tipo arquitectura basada en un único ordenador central.

A partir de mediados de los ochenta se fue extendiendo el uso de terminales “inteligentes” en forma de PC de sobremesa o portátiles que, además de teclado y pantalla, incorporan elevadas capacidades de proceso y almacenaje, de modo que los usuarios pueden procesar información localmente, de forma descentralizada y autónoma respecto al mainframe u ordenador central. Comienzan a implementarse numerosas redes locales, departamentales y corporativas.
En esta arquitectura tanto interfaz de usuario, basada en Windows, como la lógica de negocio de las aplicaciones reside en las máquinas “cliente”. Los datos residen en el servidor y son compartidos por todas las estaciones cliente.

A mediados de los noventa con el uso generalizado de Internet surge la arquitectura distribuida. Se establece una división entre los distintos niveles lógicos, necesaria para soportar las nuevas arquitecturas Internet. Implementación de dicha separación se consigue con la incorporación de un nuevo tipo de servidor: el servidor de aplicaciones. La lógica de negocio, que en la arquitectura cliente/servidor residía en el PC, es ejecutada ahora en los servidores de aplicaciones.

Como vemos en la ilustración, en la arquitectura distribuida cada nivel lógico dispone de un tipo de servidor físico especializado:
El desarrollo de esta arquitectura ha sido un facilitador para el desarrollo de Internet y llegado hasta nuestros días. La computación en la nube (cloud computing) es su último exponente.
Les propongo reflexionar sobre las ventajas e inconvenientes de las distintas arquitecturas tanto desde el punto de vista tecnológico como empresarial. En el próximo post les expondré mi visión.
¡Quedo a la espera de sus reflexiones y comentarios!
Profesor de Dirección de Sistemas y Tecnologías de la Información
Además, hemos abierto el plazo de solicitud de BECAS -100% en los siguientes programas para profesionales: Máster en Marketing Digital, en el Máster en Growth Hacking & Marketing Automation, en el Máster en Digital Analytics & Big Data, en el Máster en eCommerce y en el Máster en Google Marketing Platform.
Cada año formamos a miles de alumnos en estas áreas de conocimiento. ¡Mejora en tu carrera profesional y solicita tu plaza!. Plazas limitadas por edición e IEDGE Business School se reserva el derecho de admisión.

[lwptoc depth=»2″]
Las técnicas son los procedimientos que se usan en el desarrollo de un proyecto de auditoría informática. Estas son algunas de las técnicas más comunes y aceptadas:
Las herramientas son el conjunto de elementos que permiten llevar a cabo las acciones definidas en las técnicas. Las herramientas utilizadas son: cuestionarios, entrevistas, checklist, trazas y software de interrogación.
>> Los cuestionarios es la herramienta punto de partida que permiten obtener información y documentación de todo el proceso de una organización, que piensa ser auditado.
El auditor debe realizar una tarea de campo para obtener la información necesaria, basado en evidencias o hechos demostrables. Inicia su trabajo solicitando que se cumplimenten los cuestionarios enviados a las personas correspondientes, marcadas por el auditor. Los cuestionarios no tienen que ser los mismos en caso de organizaciones distintas, ya que deben ser específicos para cada situación.
La fase de cuestionarios puede omitirse si el auditor ha podido recabar la información por otro medio.
>> La segunda herramienta a utilizar es la entrevista, en la que llega a obtener información más específica que la obtenida mediante cuestionarios, utilizando el método del interrogatorio, con preguntas variadas y sencillas, pero que han sido convenientemente elaboradas.
>> La tercera herramienta que se utiliza es el checklist, conjunto de preguntas respondidas en la mayoría de las veces oralmente, destinados principalmente a personal técnico. Por estos motivos deben ser realizadas en un orden determinado, muy sistematizadas, coherentes y clasificadas por materias, permitiendo que el auditado responda claramente.
Existen dos tipos de filosofía en la generación de checklists:
La primera filosofía permite una mayor precisión en la evaluación, aunque depende, claro está, del equipo auditor. Los binarios, con una elaboración más compleja, deben ser más precisos.
No existen checklists estándares, ya que cada organización y su auditoría tienen sus peculiaridades.
La siguiente herramienta que se utiliza, las trazas, se basa en el uso de software, que permiten conocer todos los pasos seguidos por la información, sin interferir el sistema. Además del uso de las trazas, el auditor utilizará, los ficheros que el próximo sistema genera y que recoge todas las actividades que se realizan y la modificación de los datos, que se conoce con el nombre de log. El log almacena toda aquella información que ha ido cambiando y como ha ido cambiando, de forma cronológica.
En los últimos años se ha utilizado el software de interrogación para auditar ficheros y bases de datos de la organización.
Las herramientas de productividad permiten optimizar recursos en el desarrollo del proyecto. Las más comunes son:
Puedes asistir a nuestras clases en directo relacionadas con Marketing Digital y Comercio electrónico que organiza IEDGE Business School. Haz clic aquí para ver las próximas masterclass online.
Muchas gracias y espero sus comentarios!
Profesor de Dirección en Tecnología y Sistemas de Información
¡Puedes seguirnos en Linkedin, Facebook, Twitter, Instagram y Youtube!
Information Technology Infrastructure Library(ITIL)
ITIL fue desarrollada durante los años 1980 por la Central Computer and Telecommunications Agency (CCTA) del gobierno británico como respuesta a la creciente dependencia de las tecnologías de la información, pero no fue implementada hasta a mediados de los años 1990, con el fin de proporcionar un marco de trabajo de prácticas destinadas a facilitar la entrega de servicios de tecnologías de la información (TI). Actualmente se encuentra posicionado como uno de los estándares de calidad más utilizados a nivel mundial junto con: Information Services Procurement Library (ISPL), Application Services Library (ASL), Dynamic Systems Development Method (DSDM), Capability Maturity Model Integrated (CMM/CMMI) en la gestión de servicios informáticos. (más…)

[lwptoc]
La implantación de la cualquier tecnología dentro de una empresa se debe tomar como uno de los proyectos importantes de la empresa siendo necesario establecer un plan detallado.
Las organizaciones que intentan implantar tecnologías de la información demasiado rápidamente aumentan de forma considerable los riesgos del fracaso. Por ejemplo, desestimar la necesidad de una formación en los desarrollos realizados y no tomar en cuenta la curva de aprendizaje puede conducir al fracaso de la adopción de los nuevos sistemas.
El plan de implantación de un sistema de la información debe cubrir las siguientes consideraciones:
Los pasos para seguir una implantación de un nuevo sistema de información podríamos clasificarlos en:
1.- Planificación.
2.- Adquisición.
3.- Introducción.
4.- Utilización.
5.- Retirada.
Que veremos en el próximo post
¡Sigan atentos!
Profesor de Dirección de Sistemas y Tecnologías de la Información
¡Puedes seguirnos en Linkedin, Facebook, Twitter, Instagram y Youtube!. En IEDGE Business School apoyamos a los mejores C.V. para que avancen en una formación profesional y actualizada en Management y Finanzas.
Puedes asistir a nuestras clases en directo relacionadas con Marketing Digital y Comercio electrónico que organiza IEDGE Business School. Haz clic aquí para ver las próximas masterclass online.
Además, hemos abierto el plazo de solicitud de BECAS -100% en los siguientes programas para profesionales: Máster en Marketing Digital, en el Máster en Growth Hacking & Marketing Automation, en el Máster en Digital Analytics & Big Data, en el Máster en eCommerce y en el Máster en Google Marketing Platform.
Cada año formamos a miles de alumnos en estas áreas de conocimiento. ¡Mejora en tu carrera profesional y solicita tu plaza!. Plazas limitadas por edición e IEDGE Business School se reserva el derecho de admisión.
[lwptoc depth=»2″]
La programación consiste en proporcionar a un equipo un conjunto de instrucciones (o sentencias) que deben ser ejecutadas en orden, y que proporcionan una determinada funcionalidad al ordenador.
Internamente, los microprocesadores sólo entiende un conjunto reducido de operaciones básicas: aquellas que pertenecen a su conjunto de instrucciones. Estas instrucciones realizan tareas sencillas, como la suma de dos números, o el salto de una parte del programa a otro; para el profano parece imposible que con operaciones de tal sencillez se puedan construir complejos sistemas, tales como los que controlan el tráfico aéreo, o el intercambio de valores en bolsa.
La programación a más bajo nivel consiste en la codificación de las instrucciones básicas de procesador; es lo que se llama código máquina. Este método de codificación es lento y engorroso, y limita las posibilidades del programador. Por este motivo fueron creados los lenguajes ensambladores, que mediante una serie de comandos nemotécnicos facilitan el desarrollo y la depuración de los programas.
Sin embargo, a pesar de ser un importante avance, el lenguaje ensamblador no es apropiado para la gestión de proyectos de gran complejidad; rápidamente, el lenguaje ensamblador impone al programador demasiadas dificultades.
Por este motivo fueron creados los lenguajes de alto nivel, que libran al programador de ciertas tareas, y permiten gestionar una mayor complejidad.
Cuando se usa un lenguaje de alto nivel, un programa específico, llamado compilador , traduce el código fuente al lenguaje ensamblador de la máquina-destino. Éste es ensamblado por un programa ensamblador , y se obtiene un archivo de código objeto, que contiene una mezcla de código ejecutable y de información necesaria para el paso siguiente: el enlazado. Finalmente, el enlazador crea el programa que consta de código ejecutable y datos
Los compiladores son traductores que realizan su tarea globalmente, de forma que se analiza todo el programa fuente, se genera el código máquina correspondiente, y se almacena, todo de una vez.
Una vez realizada la traducción, el programa objeto, que se ha almacenado, se puede ejecutar tantas veces se quiera sin tener que volver a traducir. Así, el análisis, y la traducción, son secuenciales, y la ejecución es independiente.
En la etapa de generación de código se procede de forma similar a la de los intérpretes, teniendo en cuenta que se realiza sobre todo el programa. En la etapa de optimización se intenta encontrar un programa en lenguaje máquina que sea equivalente al que se ha generado, y que, además, sea más pequeño y más rápido. Aquí, el programa se almacena para su posterior ejecución.
Los compiladores permiten particionar el programa fuente en varios subprogramas. De esta forma, se usa el linker, que es una herramienta que toma como entrada varios subprogramas objeto, y devuelve un único programa objeto, llamado programa ejecutable. Generalmente, la mayor parte de estos subprogramas objetos serán de librerías e irán incluidos con el compilador.
Debido a la forma de traducir que utilizan los compiladores, estos tienen, básicamente, las siguientes características importantes:
En general, se utilizan compiladores para lenguajes de bajo nivel, donde predomine la programación de sistemas y grandes volúmenes de cálculos. Un ejemplo de lenguaje compilado es C / C++.
Los intérpretes son traductores que realizan su tarea por bloques, de forma que se van analizando bloques del programa fuente, se genera el código máquina correspondiente, y se ejecuta.
Este ciclo se repite hasta que acaba el programa. Así, el análisis, la traducción, y la ejecución están fuertemente ligadas. Los bloques de traducción corresponden a una única instrucción.
En la etapa de generación de código se busca una combinación de instrucciones en lenguaje máquina que hagan exactamente lo mismo que haría la instrucción en lenguaje de alto nivel. A cada instrucción de alto nivel le suelen corresponder varias de lenguaje máquina, tantas más cuanto más compleja sea la instrucción. En la etapa de ejecución simplemente se pasa el control al código objeto generado hasta que termine. Aquí, el programa objeto sólo está almacena por trozos y por breves instantes de tiempo.
Debido a la forma de traducir que utilizan los intérpretes, estos tienen, básicamente, la siguiente serie de características importantes:
¡Muchas gracias y espero sus respuestas!
Profesor de Dirección de Sistemas y Tecnologías de la Información
Además, hemos abierto el plazo de solicitud de BECAS -100% en los siguientes programas para profesionales: Máster en Marketing Digital, en el Máster en Growth Hacking & Marketing Automation, en el Máster en Digital Analytics & Big Data, en el Máster en eCommerce y en el Máster en Google Marketing Platform.
Cada año formamos a miles de alumnos en estas áreas de conocimiento. ¡Mejora en tu carrera profesional y solicita tu plaza!. Plazas limitadas por edición e IEDGE Business School se reserva el derecho de admisión.

[lwptoc]
La seguridad informática abarca un campo muy amplio, ya que va desde la protección del ordenador de sobremesa del que disponemos, pasando por la información disponible y alcanzando las redes que lo comunican con el mundo exterior. De ahí que la definición de seguridad sea bastante compleja y dentro de un entorno auditoría informática continua. Si que tenemos que tener claro que la seguridad del entorno informático deben basarse en:
 das accedan al sistema, ni a la información disponible. Para eso es muy importante disponer de las herramientas oportunas para el control de accesos a los sistemas y que la información confidencial sea cifrada
das accedan al sistema, ni a la información disponible. Para eso es muy importante disponer de las herramientas oportunas para el control de accesos a los sistemas y que la información confidencial sea cifradaLas políticas de seguridad informática han surgido como una herramienta en las empresas para concienciar a los usuarios sobre la importancia y la sensibilidad de la información y de los servicios de la empresa.
Una política de seguridad es la forma de comunicación con los usuarios, estableciendo un canal de actuación en relación a los recursos y los servicios informáticos de la empresa. Describe lo que se desea proteger y el porqué, mediante normas, reglamentos y protocolos a seguir, definiendo funciones y responsabilidades de los componentes de la organización y controlando el correcto funcionamiento.
Los directivos y los expertos en tecnologías de la información definen estos requisitos de seguridad, considerándola como parte de la operativa habitual y no como una acción adicional.
La creación de las políticas conlleva la creación de reglamentos de seguridad.
Las políticas de seguridad deben considerar:
Las políticas de seguridad informática deben utilizar un lenguaje sencillo, sin tecnicismos y ambigüedades, que puedan ser entendidos por todos. Deben ser actualizadas periódicamente, por ejemplo en cambios organizacionales como son el aumento de personal, desarrollo de nuevos negocios,…
Los parámetros para establecer las políticas son:
Es básico, para que las políticas de seguridad surtan efecto en una organización, que dichas políticas sean aceptadas y para ello deben integrarse en el modelo de negocio de la empresa, para que el personal entienda de su importancia.
Muchas gracias y espero sus comentarios!
Profesor de Dirección en Tecnología y Sistemas de Información
¡Puedes seguirnos en Linkedin, Facebook, Twitter, Instagram y Youtube!. En IEDGE Business School apoyamos a los mejores C.V. para que avancen en una formación profesional y actualizada en Management y Finanzas.
Puedes asistir a nuestras clases en directo relacionadas con Marketing Digital y Comercio electrónico que organiza IEDGE Business School. Haz clic aquí para ver las próximas masterclass online.
Además, hemos abierto el plazo de solicitud de BECAS -100% en los siguientes programas para profesionales: Máster en Marketing Digital, en el Máster en Growth Hacking & Marketing Automation, en el Máster en Digital Analytics & Big Data, en el Máster en eCommerce y en el Máster en Google Marketing Platform.
Cada año formamos a miles de alumnos en estas áreas de conocimiento. ¡Mejora en tu carrera profesional y solicita tu plaza!. Plazas limitadas por edición e IEDGE Business School se reserva el derecho de admisión.
Los diferentes tipos de arquitecturas de sistemas descritos en un anterior post presentan ventajas e inconvenientes tanto tecnológicos como empresariales. Vamos a repasar las ventajas e inconvenientes que me parecen más significativos en cada una de las arquitecturas.
[lwptoc]

¡Quedo a la espera de sus comentarios!
Profesor de Dirección de Sistemas y Tecnologías de la Información
Puedes asistir a nuestras clases en directo relacionadas con Marketing Digital y Comercio electrónico que organiza IEDGE Business School. Haz clic aquí para ver las próximas masterclass online.
Además, hemos abierto el plazo de solicitud de BECAS -100% en los siguientes programas para profesionales: Máster en Marketing Digital, en el Máster en Growth Hacking & Marketing Automation, en el Máster en Digital Analytics & Big Data, en el Máster en eCommerce y en el Máster en Google Marketing Platform.
Cada año formamos a miles de alumnos en estas áreas de conocimiento. ¡Mejora en tu carrera profesional y solicita tu plaza!. Plazas limitadas por edición e IEDGE Business School se reserva el derecho de admisión.

{kind=link}